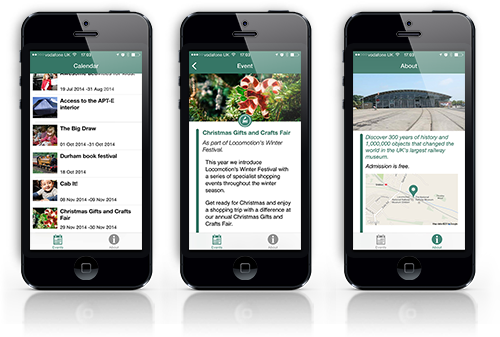
By Ben Mawhinneyon August 21, 2025in Blogwith Comments Off on The art of customer satisfaction…
You’d think that this would be quite an easy topic, after all, it was Harry Gordon Selfridge, the founder of Selfridges department store in London, around 1909, who said “The customer is always right”.
Last month, The App Chaps attended the Museum Next conference, here in our home town of Gateshead, by the banks of the River Tyne.
I wanted to attend the event as it’s always been a sector that has had a particular resonance with me – after all, when you have a three year old boy, you tend to visit a lot of museums.
We also worked with Sumo, the conference organisers, on the Rambling On app for the Museum of East Anglian Life last year and put together a proposal for the National Museum of Scotland to promote their Mammoths of the Ice Age exhibition.
Now, one of the threads that seemed to run through the conference was about apps and their suitability for a museum’s audience. I think there was a growing realisation from some sectors that just creating an app for the sake of having an app on the app store, or to tick some kind of box in the marketing plan wasn’t such a good idea. Visitors need something that adds value to their experience, or helps them to connect & create those experiences. If you saw Colleen Dilenschneider’s talk at Museum Next all about ‘touch’ then you’ll know what I’m talking about. Actually, there’s a feature in this app that was actually included on her recommendation because she suggested it was a good idea. More on that later.
Anyway, we decided that we would put our money where our mouth is and show you that it’s possible to achieve something worthwhile, which adds to your visitor experience, without having to spend five or six figures in order to validate your idea. We built and published this app during the two days that the conference was running for. Yes, technically we had a couple of people working on it at the same time, but you should get the idea. You can achieve quite a lot in a relatively short space of time if you know what you’re setting out to achieve. In terms of time, the bit that took the longest was getting a decent events feed together. We wanted to make sure that the app had no additional overhead going forward, so taking the current events on the website and passing them through into the app was an essential component to keep the administration overheads down.
So, what’s next? We’ve integrated Bluetooth into the app so that we can get some metrics on how many people who download the app then go on to visit the museum in the real world. It will be really interesting if we can see if we can link some of the archive footage to some of the exhibits, so that we can use the screen in a visitors’ pocket to provide additional context.
The museum buildings are quite spread out over the site, so we’re planning to include a map so that you can see where the key collection buildings are in relation to each other and the facilities on the site. There’s also a feed of museum related activity we’d like to include – to make their existing social media content work a little bit harder.
Now, there are a couple of things that we intend to do to make the app even better. One, is to sort the events out so that they appear in a chronological order. Seems pretty obvious, but that’s the problem when you’re scraping data from a website. If your organisation has properly structured data, with meta data (data about data) describing the elements of each event, then we should talk!
Events really do need to be categorised into Single Events (one off events), Continuous Events (that run every week, or every month, or every second Thursday of the month) and events that have a start & end date (and run for multiple days).
App facts
Length of the project: Two days’ development, one day of design Companies involved: The App Chaps Ltd., design & development Size of the team: One full-time iOS engineer, one full-time back-end engineer, one full-time designer, one full-time project manager & me.
You cancoulddownload the Locomotion app for Android from the Google Play store.
You cancouldalso download the app for iOS from the App Store.
*Not any more, once we shut the company down, we stopped publishing on the app store.
By Ben Mawhinneyon July 7, 2014in Blogwith Comments Off on Captive Minds
Here’s a preview of the Captive Minds map, embedded in a page.
If this was a blog post, then would it allow me to use multiple images in a post?
Here are a couple of screen grabs from the Velo-trainer app that show a couple of different screens within the product:
…and here are a couple more.
You can see how this post is really starting to shape up.
With a little bit of care and attention you can see how easy it is to write great looking blog posts, like this.
Ben Mawhinney, Digital Director.
That’s a block quote, and our block quote needs better styling. One to go on the list.
Updated 5th September 2025
I think I wrote this post to show someone how to edit blog posts, so it’s illustrative, as opposed to a definitive piece of site content.
However, it has reminded me that I’m supposed to be writing about more of the projects that I’ve been involved with (over the years).
The Antarctica work that we did was foundational – after all, it was the inception of an idea that eventually became a company, and a company that lasted a decade (before a combination of things managed to conspire against it). More on that, later.
The Antarctica Commissions (as I will refer to them from now on) were some of the most exciting projects I’ve ever been involved with. It’s difficult to put into words exactly why, I guess one of the reasons was that we were given free reign to design and develop the app that we wanted to build. The app also sat at the intersection of technology, education and innovation, with a healthy dose of history and the environment thrown in for free.
Coasteering in Dorset with the team that provided the expedition logistics. Coldest I’ve ever been in my life, although I don’t suppose it was even half as cold as Antarctica…
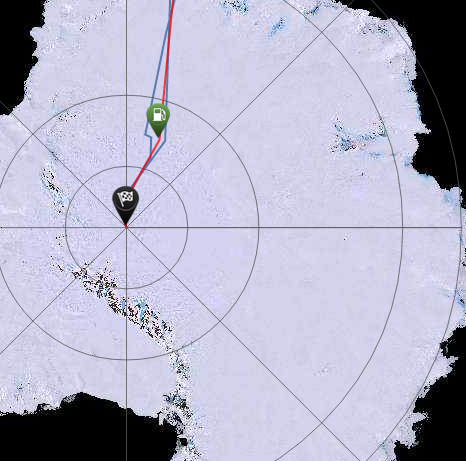
The project also gave me an opportunity to immerse myself (literally) into the very tiniest part of Antarctic exploration (behind a desk, or sat on the sofa) by providing support to an actual, live expedition. Our app sent weather observations back to the Met Office twice daily, along with the location of the expedition team every five minutes. By the end of the project we ended up using this technology to provide expedition tracking services to around seven different expeditions, including Prince Harry’s Walking With The Wounded, Parker Liautaud’s Willis Resilience and Maria Leijerstam‘s White Ice Cycle – the fastest human-powered speed record to reach the South Pole (in 10 days 14 hours and 56 minutes).
We also got the opportunity to work with Arctic Trucks, an Icelandic company who modify Toyota pickup trucks to operate more effectively in extreme climates, and they are probably one of the coolest companies I’ve ever had the privilege of working with.